一个数据中心有一万台机器,如何将这些机器连接起来?
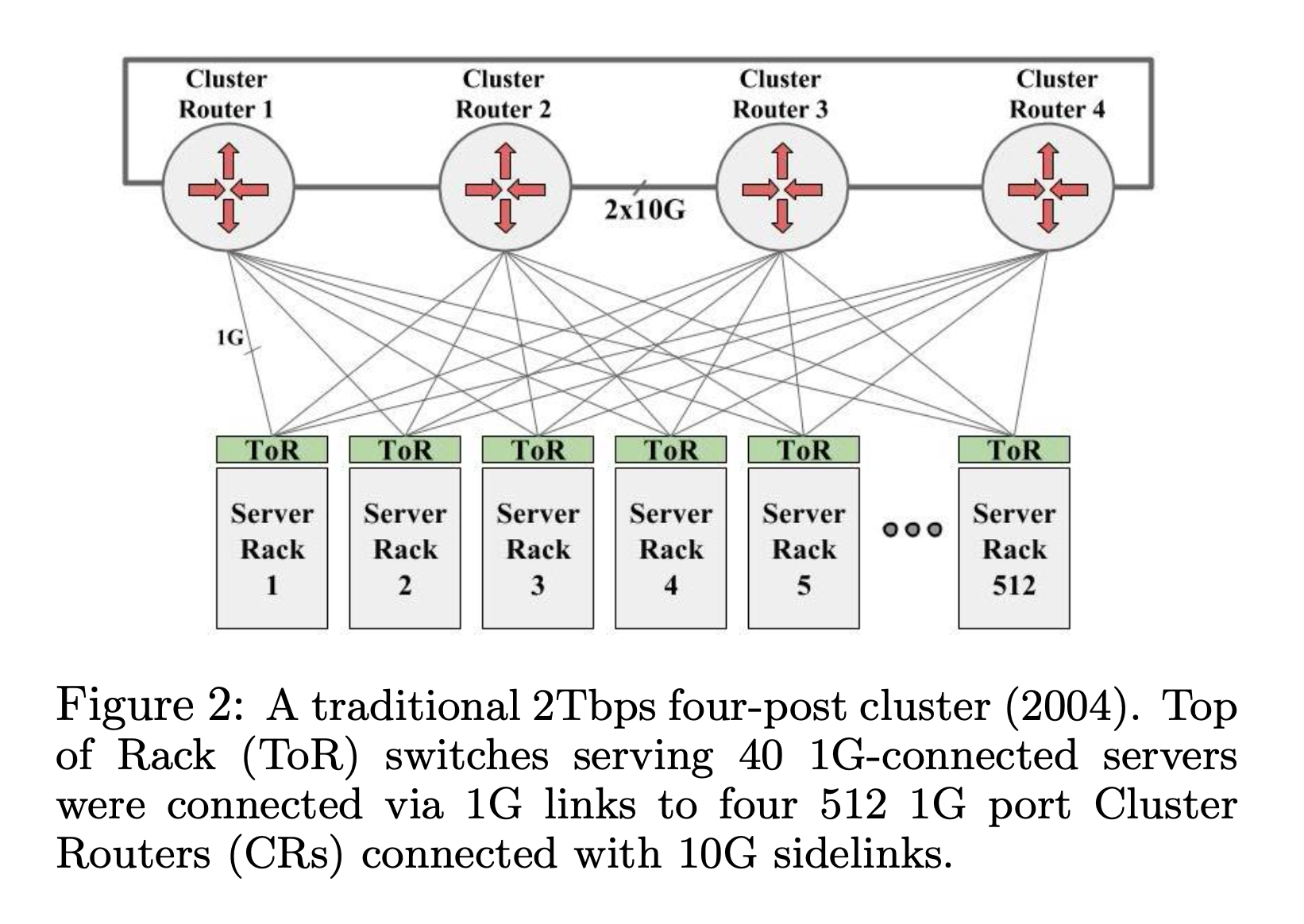
最直观的方式是在每一个 Rack (机柜)上放一个交换机 (TOR, Top-of-Rack),然后再用更大的交换机作为核心,把所有的 TOR 连接起来,组成一个集群。Google 在 2004 年使用的就是这种方式。
2004 年 Google 使用的 four-post 架构
高端的集群交换机 (CR) 有 512 ports,那么每一个 CR 可以连接 512 个 TOR,4 个 CR 可以提供 512 * 4 ports, 每一个 TOR 使用两条线连接 CR,那么一共可以支持 512 * 4 / 2 = 1024 个 TOR。每一个 TOR 支持同 Rack 的 40 个 1RU 机器,一个最大支持 4万台机器 (1024 * 40 = 40960) 的集群就组成了。
虽然支持的机器数量足够了,但是这个集群存在很多问题。
问题1: 严重的 oversubscribe,TOR 下的机器之间有 1G 带宽,但是 TOR 上行只有 2G,跨越 CR 的带宽就更小了。
严重的 oversubscribe

这对应用的扩容影响很大,如果应用之间有带宽需求,就必须使用复杂的调度算法,来让带宽需求高的应用尽可能部署在一起。Google 的业务中,搜索,广告需要大量的索引生成和存储,对东西向(服务器和服务器之间)的带宽要求越来越高,集群之间的带宽成为严重的瓶颈。
假设所有的机器点到点直接的带宽都是 1G,那应用就可以自由地扩容,调度算法就可以很简单,不必考虑 Locality,伸缩能力也更强。
理想的扁平带宽结构,所有的点对点都是1G带宽

问题2: 部署机构最好能够横夸更大的故障域。数据中心的电力是按照楼层部署的,如果电源失败,那么整层机器都会下线。所以,软件最好部署在集群的多个故障域来提高可用性。但是,这又和上面说的,要尽量把软件部署在一起来利用同集群内更高的带宽违背。这也证明了扁平化大网络的必要性。
问题3: 受集群交换机 CR 的限制。这个结构能够支持多大的规模,完全取决于集群交换机的带宽,端口数。集群交换机能做到多高端,就看思科、华为这种设备制造商的能耐了。
这些高端交换机通常成本高昂,因为这些设备的技术通常是从 ISP 下放的。高端交换机的需求大部分都在 ISP 那边,像 Google 这种数据中心规模的客户很少。以 ISP 为核心客户的交换机还有以下问题:1)交换机都是单个独立配置的,但在数据中心中都是静态的拓扑结构,大量交换机使用独立配置的方法很复杂;2)花高成本实现的 HA 对于数据中心来说不划算。WAN 线路非常昂贵,挂掉一个交换机的损失很大,所以在 ISP 这边花大成本实现 HA 是值得的。但是在数据中心,线路都是多路部署的,很便宜,交换机挂了影响也不大。这些高成本实现的高可用交换机就不划算了;3)ISP 交换机需要支持很多 feature 来满足路由 policy 的需要,也要支持很多路由协议,来满足不同的区域间路由。但是在数据中心,拓扑结构是有一个实体控制和设计的,而且是静态的,一种路由协议就足够了,所以 ISP 级的高端交换机上大部分的 feature,在数据中心是没有用武之地的。
除去这些缺点,还有一个最大的问题,就是 Google 需要的交换机在市场上买不到,无论花多少钱,都没有交换机产品能够支持 Google 的规模。
Google 把数据中心作为一个巨型计算机来使用1,把很多磁盘磁盘当作是一个大型的文件系统来用2,那么为什么不把很多个 Switch 当作一个 Switch 来用呢?
本文算是对 Google 在 2015 年发布的论文 Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network3 的精读,介绍了 Google 的数据中心网络 10 年间使用过的 5 代架构。